Thing is, for your average user with no GPU and whp never thinks about RAM, running a local LLM is intimidating. But it shouldn’t be. Any system with an integrated GPU, and the more RAM the better, can run simple models locally.
The not so dirty secret is that ChatGPT 3 vs 4 isn’t that big a difference, and neither are leaps and bounds ahead of the publically available models for about 99% of tasks. For that 1% people will ooh and aah over it, but 99% of use cases are only seeing marginal gains on 4o.
And the simplified models that run “only” 95% as well? They can use 90% fewer resources give pretty much identical answers outside of hyperspecific use cases.
Running a a “smol” model as some are called, gets you all the bang for none of the buck, and your data stays on your system and never leaves.
I’ve been yelling from the rooftops to some stupid corporate types that once the model is trained, it’s trained. Unless you are training models yourself, there is no need for the massive AI clusters, just for the model. Run it local on your hardware at a fraction of the cost.
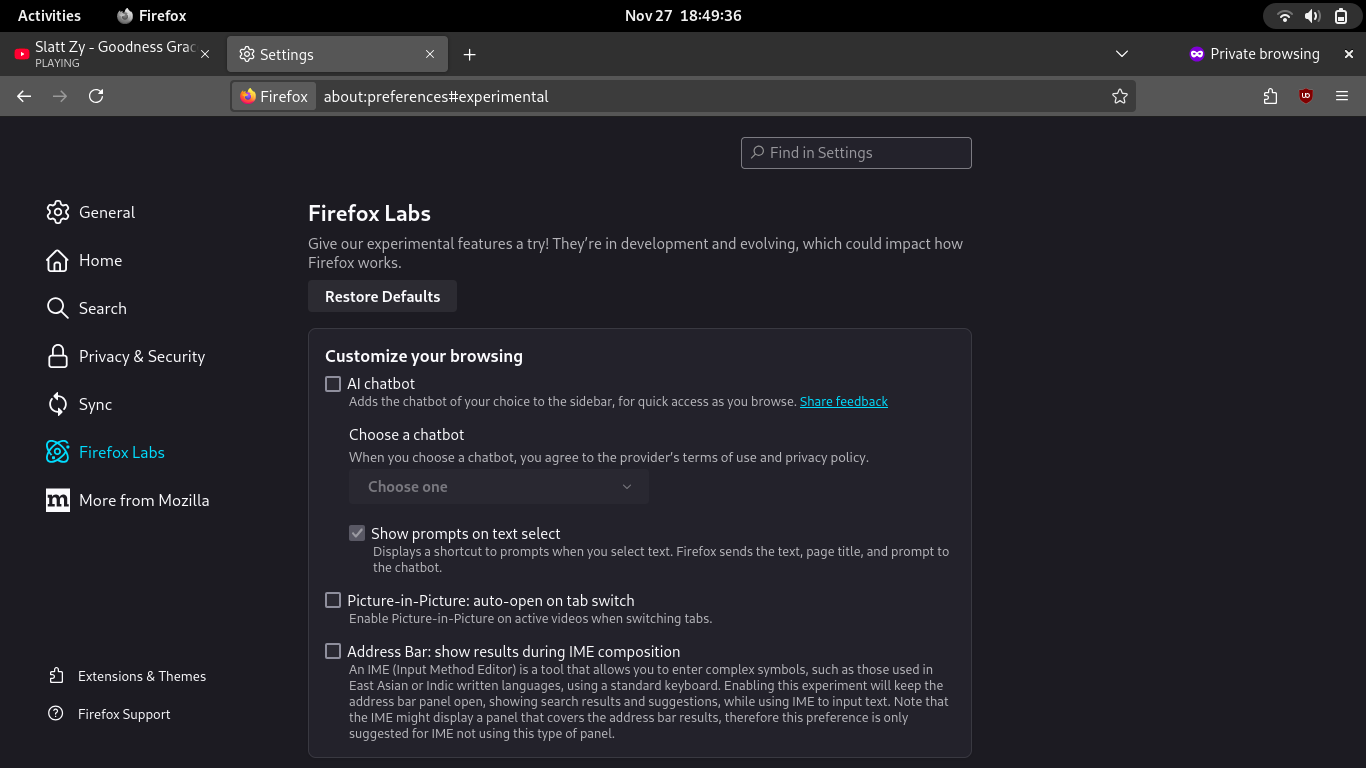
There’s the tragedy with this new feature: they fast-tracked this past more popular requests, sticking it into Release Firefox.
But they only rushed the part that connects to third parties. There was also a “localhost” option which was originally alongside the Big Five corporate offerings, but Mozilla ultimately decided to bury that one inside of the about:config settings.
I’m guessing that the reason (and a good one at that) is that simply having an option to connect to a local chatbot leads to just confused users because they also need the actual chatbot running on their system. If you can set up that, then you can certainly toggle a simple switch in about:config to show the option.
Last time I tried using a local llm (about a year ago) it generated only a couple words per second and the answers were barely relevant. Also I don’t see how a local llm can fulfill the glorified search engine role that people use llms for.
Try again. Simplified models take the large ones and pare them down in terms of memory requirements, and can be run off the CPU even. The “smol” model I mentioned is real, and hyperfast.
Anyways, how do I make these use my gpu? ollama logs say the model will fit into vram / offloaing all layers but gpu usage doesn’t change and cpu gets the load. And regardless of the model size vram usage never changes and ram only goes up by couple hundred megabytes. Any advice? (Linux / Nvidia) Edit: it didn’t have cuda enabled apparently, fixed now
Yea I don’t trust any AI models for facts, period. They all just lie. Confidently. The smol model there at least tried and got it right at first… Before confusing the sentence context.
Qwen is a good model too. But if you wanted something to run home automation or do text summaroes, smol is solid enough. I’m using CPU so it’s good enough.

{kind=link}
Thing is, for your average user with no GPU and whp never thinks about RAM, running a local LLM is intimidating. But it shouldn’t be. Any system with an integrated GPU, and the more RAM the better, can run simple models locally.
The not so dirty secret is that ChatGPT 3 vs 4 isn’t that big a difference, and neither are leaps and bounds ahead of the publically available models for about 99% of tasks. For that 1% people will ooh and aah over it, but 99% of use cases are only seeing marginal gains on 4o.
And the simplified models that run “only” 95% as well? They can use 90% fewer resources give pretty much identical answers outside of hyperspecific use cases.
Running a a “smol” model as some are called, gets you all the bang for none of the buck, and your data stays on your system and never leaves.
I’ve been yelling from the rooftops to some stupid corporate types that once the model is trained, it’s trained. Unless you are training models yourself, there is no need for the massive AI clusters, just for the model. Run it local on your hardware at a fraction of the cost.
There’s the tragedy with this new feature: they fast-tracked this past more popular requests, sticking it into Release Firefox.
But they only rushed the part that connects to third parties. There was also a “localhost” option which was originally alongside the Big Five corporate offerings, but Mozilla ultimately decided to bury that one inside of the
about:configsettings.I’m guessing that the reason (and a good one at that) is that simply having an option to connect to a local chatbot leads to just confused users because they also need the actual chatbot running on their system. If you can set up that, then you can certainly toggle a simple switch in about:config to show the option.
Can you point me to some resources to running smol llm?
My use case prob just to help “typing” miscellaneous idea I have or check for my grammatical error, in english.
Thanks, in advance.
https://ollama.com/
Here you go: Review of SmolVLM https://www.marktechpost.com/2024/11/26/hugging-face-releases-smolvlm-a-2b-parameter-vision-language-model-for-on-device-inference/
Model itself: https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
And you can use Ollama to run it locally, and Open WebUI to access it in browser.
Last time I tried using a local llm (about a year ago) it generated only a couple words per second and the answers were barely relevant. Also I don’t see how a local llm can fulfill the glorified search engine role that people use llms for.
Try again. Simplified models take the large ones and pare them down in terms of memory requirements, and can be run off the CPU even. The “smol” model I mentioned is real, and hyperfast.
Llama 3.2 is pretty solid as well.
These are the answers they gave the first time.
Qwencoder is persistent after 6 rerolls.
Anyways, how do I make these use my gpu? ollama logs say the model will fit into vram / offloaing all layers but gpu usage doesn’t change and cpu gets the load. And regardless of the model size vram usage never changes and ram only goes up by couple hundred megabytes. Any advice? (Linux / Nvidia) Edit: it didn’t have cuda enabled apparently, fixed now
Nice.
Yea I don’t trust any AI models for facts, period. They all just lie. Confidently. The smol model there at least tried and got it right at first… Before confusing the sentence context.
Qwen is a good model too. But if you wanted something to run home automation or do text summaroes, smol is solid enough. I’m using CPU so it’s good enough.
They’re fast and high quality now. ChatGPT is the best, but local llms are great, even with 10gb of vram.
Idk I noticed pretty significant differences between models of various sizes. I mean there are lots of metrics on this
https://www.vellum.ai/llm-leaderboard