

4·
4 months agoFrom what I’ve seen, it’s definitely worth quantizing. I’ve used llama 3 8B (fp16) and llama 3 70B (q2_XS). The 70B version was way better, even with this quantization and it fits perfectly in 24 GB of VRAM. There’s also this comparison showing the quantization option and their benchmark scores:
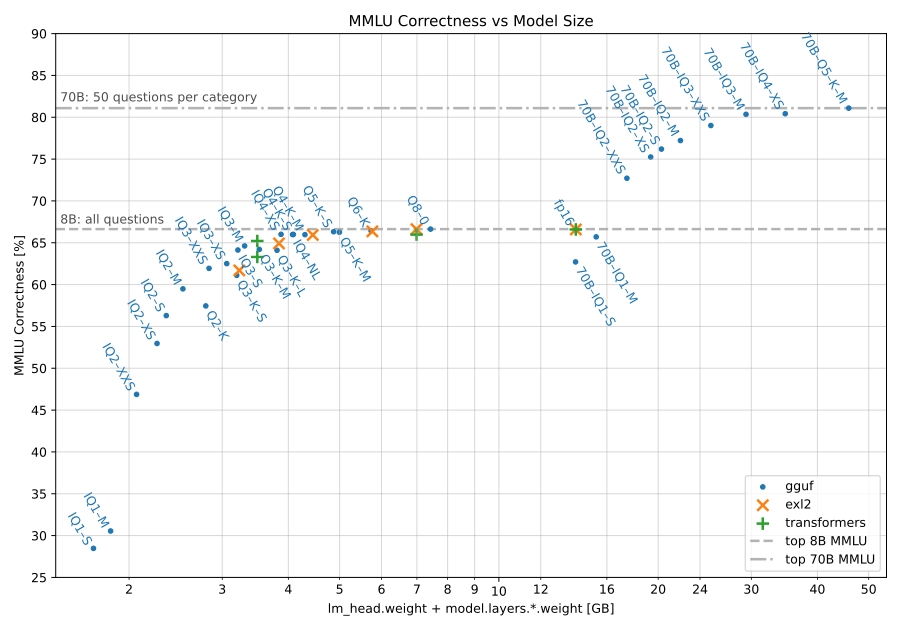
To run this particular model though, you would need about 45GB of RAM just for the q2_K quant according to Ollama. I think I could run this with my GPU and offload the rest of the layers to the CPU, but the performance wouldn’t be that great(e.g. less than 1 t/s).







I think this issue is fixed in this release.