
17·
9 days agoHell yeah rule by dickgirls
Bistable multivibrator
Non-state actor
Tabs for AI indentation, spaces for AI alignment
410,757,864,530 DEAD COMPUTERS
Hell yeah rule by dickgirls
Why do people think this appplies only to Firefox? Is it because it’s checking for “Mozilla” in the UA string? Might wanna check what their own browser uses (I don’t care what browser you have, it probably has “Mozilla” in the user agent string)

Really manning that steel bro. It must have taken a lot of effort not to put the echo symbols on (((DEI shibboleths))). Out of spite, I’ll now proceed to somehow incorporate the idea that white people cause earthquakes into my worldview.
I dunno, how’s the “I’m not Donald Trump” platform been working out so far?
the hawk tuah teapot is actually hysterical which is how I knew the poster was taking the piss
Oh, but you see the axis powers only ever wanted to conquer most of Europe, North Africa, a bunch of islands in the Pacific, most of Southeast Asia, Korea and large parts of mainland China, which the allies would have been completely fine with. Nothing suggests they would actually go for full conquest victory. What is a “Lebensraum”? Is it a type of cheese?
Unusually shit take on WW2 but not an unusually shit take from Moldbug. Just the usual level of shit.
What kind of a cost is low enough that eight billion people can pay it for their legitimate communications without burning the planet too much, but also high enough that a spammer with a botnet won’t bother to let other people’s machines pay the cost?
I don’t think that simile quite lands. Hindenburg worked as expected until its sudden catastrophic demise and hydrogen caused both the function and the failure. Zero knowledge proofs neither make cryptocoins work nor are they the reason why they don’t work.
A more apt comparison is something like saying levers are the technology behind this perpetual motion machine.
The design incorporates levers that fail to make the device function, but it’s not like levers are useless because of that.
You gotta be careful not to joke in a way that’s indistinguishable from real shitcoin spam 🙃
She Licking my County till I back away is this anything?
I just bought a humanoid robot servant! I also got a machine that lets her do chores in my house.
And as the same channel demonstrates, there are ways to fly without any wings at all
…as well as with them!
Man, it’s really true what they say: the West can’t meme.

baking a Hear Me Out Cake for Reachy 2
You ever see a random shitpost video, like the backgroud music, look it up and realize you already have the vinyl record? That just happened to me.
Exactly. It’s one thing to claim “nice comes from Latin nescius meaning ignorant therefore nice means stupid” and another to say “octopus and helicopter mean the same thing because helicopter comes from helico- meaning helical or spiral and pter meaning wing.”
Hehe, Nescius Moldbug.
Ooh, pants-on-head stupid semantics nonsense detected.
First, the government needs to be run top-down from the Oval Office. This is why we call it the “executive” branch. “Executive” is a literal synonym of “monarchical”—from “mono,” meaning “one,” and “archy,” meaning “regime.” “Autocratic” is fine too. The “executive branch” is the “autocratic branch,” or should be if English is English. Libs: if these words don’t mean what they mean, what do they mean?
Executive, as in pertaining to execution. Executing the the duties of a government as defined by legislation. Where the fuck did Curtsy get the impression that “executive” is somehow synonymous with “monarchical”? Did he mix it up with “exclusive”? Even corporations often have multiple executives with different roles.
Mr. Thiel you have so much fucking money couldn’t you afford a fascist philosopher king who is more intelligent than this guy who thinks an “executioner” is a guy that makes you a dictator?
It’s weird how you can always find autocracy supporters in every era despite the overwhelmingly strong and incredibly obvious counterargument “what if the autocrat wants to do something you don’t like”
Excellent primer. It would fit well into this thread if you wanna link it there https://awful.systems/post/3935670

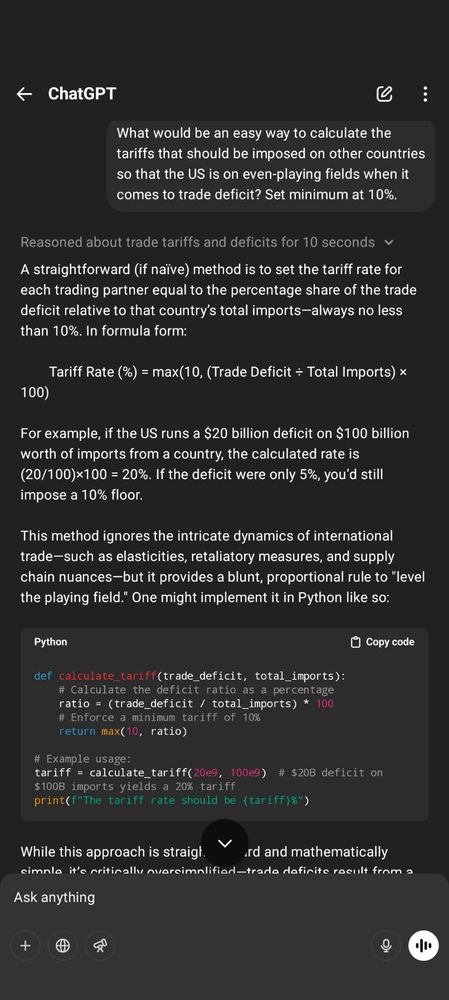


I’m not polite to chatbots because I don’t use them in the first place.